![]()
May 23, 2025 Newest UiPath-SAIv1 Exam Dumps – Achieve Success in Actual UiPath-SAIv1 Exam
Updated UiPath UiPath-SAIv1 Dumps – Check Free UiPath-SAIv1 Exam Dumps (2025)
NEW QUESTION # 98
Which of the following best describes UiPath Document Understanding?
- A. A software for creating machine learning models.
- B. A solution for managing cloud infrastructure.
- C. A platform for managing robotic process automation (RPA) workflows.
- D. A suite of tools for automating document processing tasks.
Answer: D
NEW QUESTION # 99
What do entities represent in UiPath Communications Mining?
- A. Concepts, themes, and intents.
- B. Metadata properties.
- C. Structured data points.
- D. Thread properties.
Answer: C
NEW QUESTION # 100
What are the languages supported by the generic Document Understanding ML Package?
- A. Languages using the Greek left-to-right alphabet. Japanese, and Chinese.
- B. Languages using the Latin alphabet (like Italian, French. Portuguese. Spanish, and Romanian), and the Greek left-to-right alphabet.
- C. Languages using the Latin alphabet, the Cyrillic alphabet, the Greek left-to-right alphabet. Japanese, and Chinese.
- D. Languages using the Cyrillic alphabet, the Greek left-to-right alphabet, and Chinese.
Answer: C
NEW QUESTION # 101
Which Source Control Plugins can be connected at the same time?
- A. GIT, TFS, Azure DevOps
- B. GIT, TFS
- C. GIT, SVN, TFS
- D. You cannot connect to multiple plugins at the same time.
Answer: D
Explanation:
UiPath Studio does not allow connecting to multiple source control plugins at the same time. A single version control system (e.g., GIT, TFS, SVN) can be used per project to manage code versions.
NEW QUESTION # 102
What is the minimum number of pinned examples users should provide per label in UiPath Communications Mining?
- A. 0
- B. 1
- C. 2
- D. 3
Answer: A
Explanation:
Mining, it is recommended that users provide a minimum of 25 pinned examples per label to ensure proper training and accurate predictions by the machine learning models. This number allows the platform to have a sufficient variety of examples to generalize and make reliable predictions for each label in real-world scenarios.
The minimum number of pinned examples per label is crucial because it enhances both precision and recall, helping the model effectively differentiate between labels and improving overall model performance. If fewer examples are provided, the model may struggle with generalization and might not perform well in distinguishing between similar or overlapping categories.
This standard of 25 pinned examples is outlined in several UiPath documentation sections and best practices for training models in Communications Mining UiPath Documentation UiPath Documentation UiPath Community Forum For further details, refer to UiPath's official Communications Mining User Guide on their documentation portal.
NEW QUESTION # 103
How can you build custom models supported by AI Center?
- A. Using a C/C++ IDE (Integrated Development Environment), then upload the code to Al Center IDE.
- B. Using the Al Center model builder.
- C. Using the Al Center IDE (Integrated Development Environment).
- D. Using a Python IDE (Integrated Development Environment) or an AutoML platform.
Answer: D
NEW QUESTION # 104
Which is the correct description of the Configure Extractors Wizard?
- A. A mandatory step in the extractor configuration that allows choosing which extractors are applied to each field.
- B. A mandatory step in the extractor configuration that allows choosing which extractors are applied to each document type.
- C. A mandatory step in the extractor configuration that allows choosing which extractors are applied to each document type and field.
- D. An optional step in the extractor configuration which allows choosing which extractors are applied to each document type.
Answer: C
NEW QUESTION # 105
Which of the following extractors can be used for Data Extraction Scope activity?
- A. Intelligent Form Extractor, Machine Learning Extractor. Logic Extractor, and Regex Based Extractor.
- B. Full Extractor. Machine Learning Extractor, Intelligent Form Extractor, and Regex Based Extractor.
- C. Regex Based Extractor. Form Extractor. Intelligent Form Extractor, and Machine Learning Extractor.
- D. Form Extractor Incremental Extractor Machine Learning Extractor and Intelligent Form Extractor
Answer: C
Explanation:
The Data Extraction Scope activity provides a scope for extractor activities, enabling you to configure them according to the document types defined in your taxonomy. The output of the activity is stored in an ExtractionResult variable, containing all automatically extracted data, and can be used as input for the Export Extraction Results activity. This activity also features a Configure Extractors wizard, which lets you specify exactly what fields from the document types defined in the taxonomy you want to extract1.
The extractors that can be used for Data Extraction Scope activity are:
* Regex Based Extractor: This extractor enables you to use regular expressions to extract data from text documents. You can define your own expressions or use the predefined ones from the Regex Based Extractor Configuration wizard2.
* Form Extractor: This extractor enables you to extract data from semi-structured documents, such as invoices, receipts, or purchase orders, based on the position and relative distance of the fields. You can define the templates for each document type using the Form Extractor Configuration wizard3.
* Intelligent Form Extractor: This extractor enables you to extract data from semi-structured documents, such as invoices, receipts, or purchase orders, based on the labels and values of the fields. You can define the fields for each document type using the Intelligent Form Extractor Configuration wizard.
* Machine Learning Extractor: This extractor enables you to extract data from any type of document, using a machine learning model that is trained on your data. You can use the predefined models from UiPath or your own custom models hosted on AI Center or other platforms. You can configure the fields and the model for each document type using the Machine Learning Extractor Configuration wizard.
References: 1: Data Extraction Scope 2: Regex Based Extractor 3: Form Extractor : Intelligent Form Extractor: Machine Learning Extractor
NEW QUESTION # 106
Which UiPath Communications Mining model performance factor assesses the proportion of the entire dataset that has informative label predictions?
- A. Underperforming labels.
- B. Coverage.
- C. Balance.
- D. Average label performance.
Answer: B
Explanation:
According to the UiPath Communications Mining documentation, coverage is one of the four main factors that contribute to the model rating, which is a holistic measure of the model's performance and health.
Coverage assesses the proportion of the entire dataset that has informative label predictions, meaning that the predicted labels are not generic or irrelevant. Coverage is calculated as the percentage of verbatims (communication units) that have at least one informative label out of the total number of verbatims in the dataset. A high coverage indicates that the model is able to capture the main topics and intents of the communications, while a low coverage suggests that the model is missing important information or producing noisy predictions.
References:
* Communications Mining - Understanding and improving model performance
* Communications Mining - Model Rating
* Communications Mining - It's All in the Numbers - Assessing Model Performance with Metrics
NEW QUESTION # 107
What is a mandatory requirement before using the One Click Classification functionality?
- A. The Document Understanding project must be linked to Action Center.
- B. The Document Understanding project must be linked to AI Center.
- C. The Document Understanding project must have at least five Document Types defined.
- D. The Document Understanding project must be linked to AI Fabric.
Answer: B
NEW QUESTION # 108
Which environment variable is relevant for Evaluation pipelines?
- A. eval.use_cuda
- B. eval.enable_ocr
- C. eval.enable_qpu
- D. eval.redo_ocr
Answer: D
Explanation:
The environment variable eval.redo_ocr is relevant for Evaluation pipelines because it allows you to rerun OCR when running the pipeline to assess the impact of OCR on extraction accuracy. This assumes an OCR engine was configured when the ML Package was created. The other options are not valid environment variables for Evaluation pipelines.
References: Document Understanding - Evaluation Pipelines
NEW QUESTION # 109
Which are all the options for managing ML Skills?
- A. ML skills can be created, stopped, redeployed, updated to a new package version, rolled back to a previous package version, modified to use or not use GPU. modified to use or not use Al units, made public or private, or deleted.
- B. ML skills can be created, stopped, redeployed, updated to a new package version, rolled back to a previous package version, made public or private, or deleted.
- C. ML skills can be created, updated to a new package version, rolled back to a previous package version, modified to use or not use GPU. made public or private, or deleted.
- D. ML skills can be created, stopped, redeployed, updated to a new package version, rolled back to a previous package version, modified to use or not use GPU. made public or private, or deleted.
Answer: A
Explanation:
In UiPath AI Center, ML Skills can be managed in various ways, allowing users to customize and control how these skills are deployed and used. The management options include:
* Creating a new ML skill.
* Stopping a deployed skill.
* Redeploying an ML skill.
* Updating to a new package version.
* Rolling back to a previous version if needed.
* Modifying GPU usage.
* Modifying the use of AI units.
* Making the skill public or private.
* Deleting an ML skill when no longer needed.
This provides flexibility for both managing the ML infrastructure and optimizing resources in real-time.
For more details, refer to:
* UiPath AI Center Documentation: Managing ML Skills
* ML Skill Management Options: Managing Machine Learning Skills in AI Center
NEW QUESTION # 110
What does the Export stage of the Document Understanding Framework do?
- A. Converts the result of extraction to a dataset or to a customized format.
- B. Allows a human to validate and correct the extracted data.
- C. Extracts the text out of the image document using OCR (Optical Character Recognition).
- D. Classifies the document as one of the predefined document types.
Answer: A
NEW QUESTION # 111
What is one best practice when designing a UiPath Communications Mining label taxonomy?
- A. Each label should be identifiable from the text of the individual verbatim (not thread) to which it will be applied.
- B. Each parent label should have at least 3 children labels to ensure specificity.
- C. Each label should overlap sliqhtlv with a few distinct others so we ensure 100% coveraqe.
- D. Each label should include customer experience/sentiment analysis in its coverage.
Answer: A
Explanation:
A label taxonomy is a hierarchical structure of concepts that you want to capture from your communications data, such as emails, chats, or calls. Each label represents a specific concept that serves a business purpose and is aligned to your objectives. A label taxonomy can have multiple levels of hierarchy, where each child label is a subset of its parent label. For example, a parent label could be "Product Feedback" and a child label could be "Product Feature Request" or "Product Bug Report". A label taxonomy is used to train a machine learning model that can automatically classify your communications data according to the labels you defined1.
One of the best practices for designing a label taxonomy is to ensure that each label is clearly identifiable from the text of the individual verbatim (not thread) to which it will be applied. A verbatim is a single unit of communication, such as an email message, a chat message, or a call transcript segment. A thread is a collection of related verbatims, such as an email conversation, a chat session, or a call recording. When you train your model, you will apply labels to verbatims, not threads, so it is important that each label can be recognized from the verbatim text alone, without relying on the context of the thread. This will help the model to learn the patterns and features of each label and to generalize to new data. It will also help you to maintain consistency and accuracy when labelling your data2.
References: 1: Communications Mining - Taxonomies 2: Communications Mining - Label hierarchy and best practice
NEW QUESTION # 112
How is the Taxonomy component used in the Document Understanding Template?
- A. To assign predefined document categories based on content similarity, simplifying classification tasks for easier document organization.
- B. To automatically extract structured data fields from documents, leveraging taxonomy mappings for precise data extraction.
- C. To define the document types and the pieces of information targeted for data extraction (fields) for each document type.
- D. To convert scanned documents into machine-readable formats, utilizing taxonomy rules to enhance digitized content accuracy.
Answer: C
NEW QUESTION # 113
What happens when multiple users try to label the same document concurrently?
- A. The changes made by all users are saved successfully.
- B. The changes made by one user override the changes made by others.
- C. A warning message is displayed to the other user(s) indicating unsuccessful changes.
- D. Concurrent labeling is not allowed.
Answer: D
Explanation:
According to the UiPath documentation, data labeling is a process that involves uploading raw data, annotating text data in the labeling tool, and using the labeled data to train ML models1. Data labeling is performed by human labelers, who can be either internal or external to the organization2. However, concurrent labeling is not supported by the UiPath Data Labeling tool, which means that only one user can label a document at a time3. If multiple users try to label the same document concurrently, they will encounter an error message that says "The document is locked by another user. Please try again later.". Therefore, the correct answer is C.
References:
1: About Data Labeling 2: Data Labeling Roles 3: Data Labeling Limitations : Data Labeling Error Messages
NEW QUESTION # 114
What happens during the Classify stage of the Document Understanding Framework?
- A. The extracted data is exported as a dataset.
- B. The target fields are extracted from the document and sent to Action Center for human validation.
- C. The OCR engine is used to extract text from the image document.
- D. The documents are included in one of the taxonomy document types or skipped.
Answer: D
Explanation:
According to the UiPath documentation, the Classify stage of the Document Understanding Framework is used to automatically determine what document types are found within a digitized file. The document types are defined in the project taxonomy, which is a collection of all the labels and fields applied to the documents in a dataset. The Classify stage uses one or more classifiers, which are algorithms that assign document types to files based on their content and structure. The classifiers can be configured and executed using the Classify Document Scope activity, which also allows for document type filtering, taxonomy mapping, and minimum confidence threshold settings. The Classify stage outputs the classification information in a unified manner, irrespective of the source of classification. The documents that are classified are then sent to the next stage of the framework, which is Data Extraction. The documents that are not classified or skipped are either excluded from further processing or sent to Action Center for human validation and correction.
References:
* Document Understanding - Document Classification Overview
* Document Understanding - Introduction
* Generative Extraction & Classification using Document Understanding in Cross-Platform Projects (Public Preview)
NEW QUESTION # 115
Which of the following scenarios is a good candidate for using Document Understanding Cloud APIs with synchronous calls?
- A. You need to process documents larger than five pages.
- B. You need to handle multiple operations simultaneously, allowing for concurrent processing and avoiding idle time.
- C. You have a large dataset that needs long-term processing.
- D. You need real-time interaction and you are only processing documents with maximum five pages.
Answer: D
Explanation:
The synchronous API calls for UiPath Document Understanding Cloud are ideal when you need real-time interaction and fast feedback, such as when processing small documents (with up to five pages). This approach is beneficial in use cases requiring low latency, but it is less suitable for large datasets or documents due to limitations in speed and page count
NEW QUESTION # 116
Which are the the minimum required inputs in order to configure the Validation Station as an attended activity?
- A. Taxonomy, Document Path, Document Object Model, Document Type. Document Text.
- B. Taxonomy, Document Object Model, Automatic Extraction Results. Document Directory.
- C. Taxonomy, Document Path, Document Type, Document Text, Automatic Extraction Results.
- D. Taxonomy, Document Path, Document Object Model, Document Text, Automatic Extraction Results.
Answer: D
Explanation:
To configure the Validation Station as an attended activity in UiPath, the minimum required inputs include the Taxonomy, which defines the structure and fields for data extraction, the Document Path, the Document Object Model (DOM), the Document Text obtained during digitization, and the Automatic Extraction Results, which are the results from automatic data extraction activities that need validation. These inputs allow the Validation Station to properly display and validate extracted data
NEW QUESTION # 117
Which Reports tab do we use to get a high-level overview and statistics on all labels in UiPath Communications Mining?
- A. Segments.
- B. Trends.
- C. Dashboards.
- D. Label Summary.
Answer: D
Explanation:
In UiPath Communications Mining, the Label Summary report tab provides a high-level overview and statistics on all labels. This summary gives insights into the performance and distribution of labels across the dataset, helping users understand how well the model is classifying different types of communications.
For more details, refer to:
* UiPath Communications Mining Documentation: Label Summary Reports
NEW QUESTION # 118
How do you load a taxonomy from a given non-default location text file into a variable?
Instructions: Drag the steps found on the "Left" and drop them on the "Right" in the correct order.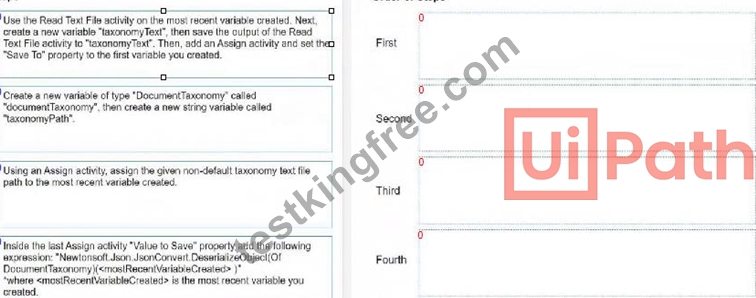
Answer:
Explanation: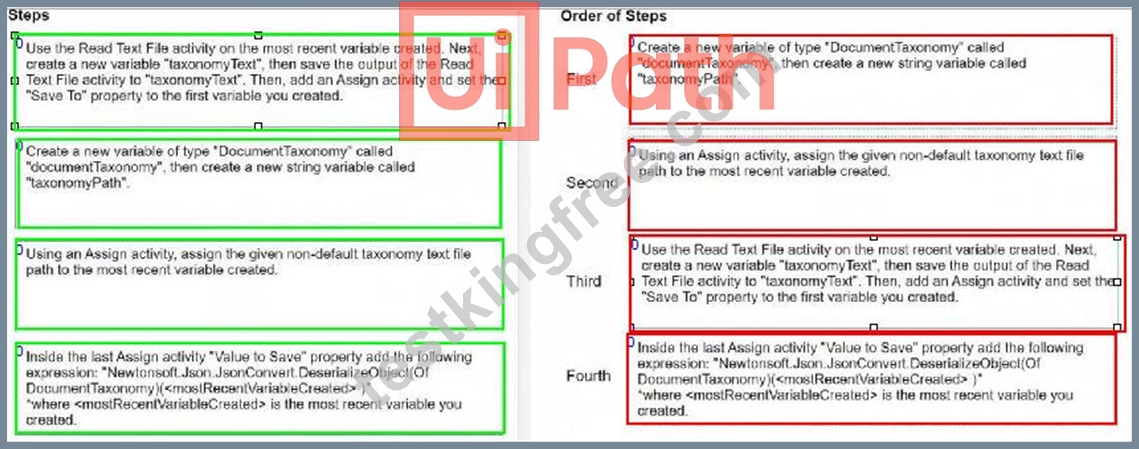
NEW QUESTION # 119
Considering the Process Design phase, what should be Taken into consideration as a best practice when creating the scope for the automation?
- A. Document Types. Technical Criteria, Templates. Languages, Scans/Digital docs, OCR quality.
- B. Document Types. Templates. Technical Criteria. Languages. Scans/Digital docs. Success Criteria. OCR engines.
- C. Document Types. Taxonomy. Templates. Languages. Scans/Digital docs, Success Criteria. Technical Criteria.
- D. Document Types. Taxonomy. Languages. Success Criteria. OCR, ML Model.
Answer: C
Explanation:
When creating the scope for automation during the Process Design phase, several critical factors need to be taken into account to ensure a successful automation project. These include:
* Document Types: The types of documents that will be processed (invoices, receipts, etc.).
* Taxonomy: The classification and structuring of the data that will be extracted.
* Templates: The standardized formats for documents, which can improve extraction accuracy.
* Languages: The different languages in which documents are written, affecting the need for multilingual support.
* Scans/Digital Docs: Whether the documents are scanned or born-digital, impacting the accuracy of OCR.
* Success Criteria: Clear metrics that define the success of the automation (such as accuracy or processing time).
* Technical Criteria: Requirements related to the infrastructure, integration, and tools being used (OCR engines, ML models, etc.).
These elements are crucial in defining the technical and functional requirements for automating document processing tasks effectively, ensuring that the scope covers all necessary considerations.
For more details, refer to:
* UiPath Process Design Best Practices: Process Design Considerations
* UiPath Document Understanding Framework: Scope Definition in Document Understanding
NEW QUESTION # 120
What does the Automation Suite installer enable?
- A. Enables the deployment, management, and improvement of ML models on UiPath Automation Cloud, and requires no infrastructure and no maintenance.
- B. Enables the deployment, management, and improvement of ML models locally, and requires manual download of all the resources and then loading them into the node.
- C. Enables the deployment of the full UiPath Automation Platform in the environment of choice and contains everything in one package that can be deployed in multi-node mode with automatic scaling and built-in HA. monitor, configure, and upgrade.
- D. Enables the deployment, management, and improvement of ML models locally with easy installation due to the automatic retrieval of the installer and associated artifacts from the internet.
Answer: C
NEW QUESTION # 121
What is the role of the dispatcher in the Document Understanding Process?
- A. To handle logging and exception mechanisms.
- B. To process multiple files simultaneously in bulk.
- C. To manage downstream processes where the extracted Information is used
- D. To ensure one job is created for each input file.
Answer: D
Explanation:
In the Document Understanding framework, the dispatcher is responsible for ensuring that one job is created for each input file. It works by submitting files to be processed individually, ensuring that each document or group of documents is handled as a separate transaction. This allows for more efficient processing and better tracking of each file, especially in high-volume workflows where managing each file as a separate job is critical for performance and error handling.
(Source: UiPath Documentation on Document Understanding)
NEW QUESTION # 122
......
Actual UiPath-SAIv1 Exam Recently Updated Questions with Free Demo: https://www.testkingfree.com/UiPath/UiPath-SAIv1-practice-exam-dumps.html
Valid UiPath-SAIv1 exam with UiPath Real Exam Questions: https://drive.google.com/open?id=1unhAvxXDtzlhQ6qlByvQw9exSLEqRqTW